The fundamental building block of a partonomy is the relation “part of,” and it links vertically from a lower level to a higher level in a partonomic neighborhood. Sympositions and their symponents do not often belong to the same population because they are rarely particularly similar;1 thus, a population generally resides on one, given level of a partonomy. Consequently, distillations of populations do have specific vertical localizations in the Logos even though they do not have specific horizontal, i.e. quasi-spatial, localizations like individuals and populations. Similarity, however, is obviously a matter of degree, so a population can be subdivided into subpopulations expressing greater similarity or collected into superpopulations expressing less. Subpopulations and superpopulations can both be distilled, and they can be linked by the horizontal relation “type of” into a hierarchical structure similar to a partonomy. Such a structure is a taxonomy. For instance, with the population of mammals, one can take the subpopulation of primates and the superpopulation of vertebrates. Primates are a type of mammal, and mammals are a type of vertebrate, and these relations extend within the very large and hierarchical Linnaean taxonomy of the “tree of life,” which is both a colorful metaphor and a precise mathematical expression.2
This analysis suggests that taxonomies are always trees. There are two ways in which taxonomies can fail to be trees. Recall the population of raindrops from Figure 1 in the last chapter. Take a raindrop with -30 microstatcoulombs of charge and build a hierarchy of subpopulations that allow for increasingly more variation from it. We can specify the subpopulation of raindrops with -60 to 0 mstatC of charge, and then incorporating that one in a bigger one we can specify the subpopulation of raindrops with -90 to 30 mstatC. We can, however, select a different raindrop with, say, -40 mstatC of charge and build a different hierarchy of subpopulations from it: -70 to -10 mstatC and then -100 to 20 mstatC. These latter sets neither contain nor are able to be contained by their former counterparts. So we have two different and irreconcilable possibilities for the hierarchy of subpopulations of raindrops, neither of which seems ‘better’ in any naïve sense.
The problem, of course, is that I’m forcing hierarchical structure onto the distribution of raindrops when it simply isn’t there. This is true in general for populations with one mode, and we can say that such populations exhibit continuous variation because there is a continuum of possibilities for the relevant parameter with no non-arbitrary location to divide it. Populations that can be divided and for which the divisions can be organized hierarchically exhibit linnaean variation, as the Linnaean taxonomy is the prime example. If you imagine the modes of a population with linnaean variation as being primitives that can be sem-linked, then the partonomy of its histogram is its taxonomy! Once again there is a strong analogy between physical space and parameter spaces, and there is a likeness between the vertical (“part of”) and horizontal (“type of”) orientations in the Logos.
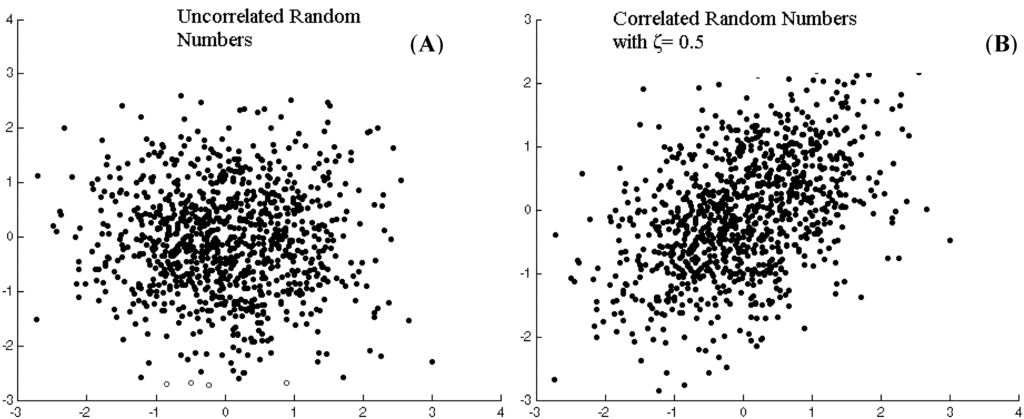
We have only considered a one-dimensional parameter space for the raindrops, that of the charge; we could consider two or more dimensions simultaneously, such as both charge and mass. In that more general case, the raindrops could be said to exhibit multivariate continuous variation, contrasting with the univariate continuous variation over a one-dimensional parameter space. It’s possible that the values of the data points in two or more dimensions of a parameter space are correlated with each other. Raindrops with a greater charge may generally have more mass, but perhaps not in a perfectly predictable way. Thus charge and mass could be correlated in raindrops, but without being interchangeable measures. This correlation would depopulate certain areas of the histogram, but without changing the number of modes. This can be called interdependent multivariate continuous variation, in contrast with independent multivariate continuous variation when there is no correlation. By necessity, all independent and interdependent variation is multivariate, because you need at least two dimensions to have a correlation, so the “multivariate” can be dropped, e.g. as just independent or interdependent continuous variation.
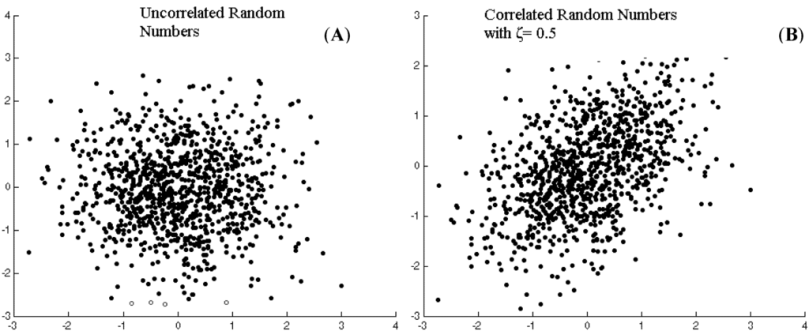
Figure 1. Independent and interdependent continuous variation. On the right, the NW and SE parts of the distribution are slightly underpopulated, and the NE and SW parts of the distribution are slightly overpopulated, making the two parameters correlated. http://www.mdpi.com/applsci/applsci-03-00107/article_deploy/html/images/applsci-03-00107-g001-1024.png
Linnaean variation is a special case of discrete variation, which pertains to those populations that have more than one mode. Every population exhibits exactly one of continuous or discrete variation, given some parameter space like the natural one, since the number of modes is either one or more than one.3 In discrete variation that is not linnaean, the modes cannot be sem-linked together to create a single hierarchical tree. For instance, imagine a population of pea plants that can either be short or tall, depending on some gene with two forms or “alleles,” and can either have constricted or full pods, depending on some other gene with two alleles. Then the individuals have four ways for combining the two characteristics: they can be short with constricted pods, short with full pods, tall with constricted pods, or tall with full pods. The individuals can be plotted in a two-dimensional parameter space of plant height and pod volume. Within this parameter space there will be four modes, each having some small amount of spread. This would be an example of multivariate discrete variation.
The question then arises as to which two pairs of modes should be sem-linked first. Should we have {{{tall and full}d, {tall and constricted}d}d, {{short and full}d, {short and constricted}d}d}d or {{{tall and full}d, {short and full}d}d, {{tall and constricted}d, {short and constricted}d}d}d? Neither of these is more forthcoming than the other unless one of height or pod shape is artificially considered primary and the other secondary. Consequently, the taxonomy of the population is not a hierarchical tree, but it is instead a combinatorial crossing between all the possibilities of each allelic modularity. This is basically the same concept as the cartesian product in set theory, so I call such variation cartesian variation. Cartesian variation can be either independent or interdependent, for instance if a pea plant being tall makes it more likely or less likely to have full pods, rather than being neutral.
In sum, there is continuous variation for distributions with one mode and discrete variation for distributions with more than one mode. Discrete variation is perfected in either linnaean or cartesian variation, which are mutually exclusive. Moreover, all of these varieties of variation can be fit into a single framework. Let’s take another detour through math to demonstrate. Pascal’s triangle is a very straightforward mathematical object that is constructed as follows: take a blank sheet of paper and write a “1” in the top center. This will be the first line. Now put zeros on both sides of the one: “0 1 0.” Now for every adjacent pair of numbers on the top line, write their sum in between them on the second line. The first pair, “0 1,” adds to 1, and the second pair, “1 0,” also adds to 1: so the second line is “1 1.” Once again put zeros on both sides of the second line, “0 1 1 0,” and construct the third line in the exact same way: “1 2 1.” The fourth line is “1 3 3 1,” the fifth “1 4 6 4 1,” the sixth “1 5 10 10 5 1,” etc.

Figure 2. Pascal’s triangle. You can imagine zeros along the outside. https://upload.wikimedia.org/wikipedia/commons/thumb/4/4b/Pascal_triangle.svg/2000px-Pascal_triangle.svg.png
If you add all the numbers in a line, you get 1 for the first line, 2 for the second, 4, 8, 16, and the subsequent powers of 2. This doubling happens because each number in each line manifests twice in the sums below it. We can imagine averaging each pair of numbers instead of adding them. Doing so would make each line sum to exactly 1 and would give us Pascal’s normalized triangle. The nth line of Pascal’s normalized triangle is, among other things, the distribution of probabilities for n coin tosses that come up the same as the first toss, also known as the binomial distribution. Each normalized line can thus be considered as a probability density function, which is an expression of what the histogram over a parameter space is likely to be. As n gets larger and larger the resulting series of numbers in line n of Pascal’s triangle gets closer and closer to approximating a curve called a gaussian, popularly known as the “bell curve.” Since every line of Pascal’s triangle approximates a gaussian and every line is a split and shifted and added copy of the one above it, it follows that gaussians retain their shape under the operation of “splitting-shifting-adding”—and for the normalized triangle more appropriate for probability distributions—“splitting-shifting-averaging.”
Imagine instead of starting with “1” at the top of the page, we started with “1 0 0 1.” I don’t believe there is any sense in which “1 0 0 1” approximates a gaussian. Our subsequent lines would be “1 1 0 1 1,” “1 2 1 1 2 1”; but after that, it’s stops being so trivial: “1 3 3 2 3 3 1,” “1 4 6 5 5 6 4 1,” “1 5 10 11 10 11 10 5 1,” “1 6 15 21 21 21 21 15 6 1.” The last computed line no longer has a dip in the middle. After several iterations, it is now approximating a gaussian! Or at least it now has one mode. In fact, it is irrelevant what string of numbers you put at the top of your page, as long as it’s finite; any string will eventually become monomodal and after that start approximating a gaussian at some line, although your paperage may vary.4
We can reverse the process and split a single mode by over-shifting. Say we’re at the third line of the triangle: “1 2 1.” We split: “1 2 1,” “1 2 1.” We should get to “1 3 3 1” after shifting and adding but we shift too much: “1 2 1 0 0 0 0 1 2 1.” If we keep iterating, we’ll eventually recuperate a gaussian, but for now we’re experiencing a setback. Shifting too much doubled the number of modes. Splitting-shifting-adding, or what we can call broken symmetries, can account for both discrete and continuous variation, depending on how big the shifts are. Symmetry belongs to subpopulations that are alike, and it is broken when a factor is introduced that differentiates them. In plants, there is usually a whole array of genes that can affect height. If each of these genes comes in a taller and a shorter allele, then whether the resulting distribution is monomodal or multimodal depends on the profile of overlap between the “shifts” corresponding to the difference in height of a pair of alleles of the same gene. If all of these are small and of comparable size, then the population will have one mode, but if one of them is substantially bigger than all the rest, then it will have two modes.
These considerations are all of one-dimensional parameter spaces, however. This results from the two-dimensionality of the paper used to construct Pascal’s triangle, one of whose dimensions is taken for the splitting-shifting-adding operation. Imagine replicating the sheet of paper with its possibly mutant triangle, stacking the copies, and splitting-shifting-adding through the sheets of paper simultaneously as across them. This can theoretically be done in even higher dimensions, accounting for parameter spaces of arbitrary dimensionality. If the introduction of broken symmetries adding new dimensions is always done to the entirety of the distribution, then cartesian variation is accounted for. If the addition of a new dimension is done to one mode at a time, then linnaean variation is accounted for. Whether mode-multiplying factors are applied always to all modes together or never to more than one mode is the factor differentiating cartesian and linnaean variation. Intermediate possibilities can be procured, and these would deliver mixtures of linnaean and cartesian variation.5 Finally, there’s a distinct similarity between independent continuous variation and independent cartesian variation. Both of these are created by many independent symmetry-breaking factors, except that in the independent cartesian case, there are a few factors that have much larger shifts than the rest, with the distribution of these factors being, in effect, multimodal.
I have developed a taxonomy for the population of populations based on the characteristics of populations’ distributions. We can ask what variation this taxonomy expresses. A distribution is either continuous or discrete. This variation is discrete. Both discrete and continuous distributions can either be univariate or multivariate; this variation is cartesian. Only multivariate distributions can be interdependent or independent; this variation is linnaean. I haven’t spent much time on this, but monomodal distributions can be gaussian or logistic or otherwise depending on a large family of parameters used as multipliers or exponents or otherwise in the equations defining many types of distributions.6 The parameter space of distributions does not have a specific dimensionality since not every distribution uses every parameter, but the framework of this chapter is sufficiently flexible to account for this and many other polymorphisms of the distribution of distributions.
Footnotes
1. Sympositions similar to their symponents would be similar to fractals. Sympositions like mountainscapes and shorelines would be well-known examples of this.
2. “Tree” was defined in Chapter 3 as a connected graph with no loops in it.
3. The number of modes isn’t always clear, but that’s what statistical techniques are for.
4. This is also related to the fact that the limit of n-fold autoconvolution is always a gaussian.
5. There’s one specific mixture of linnaean and cartesian variation that I would like to see implemented. There are two popular ways to organize email archives. One is to put individual emails in folders, which can then be put into folders, into folders, etc. The other is to create labels and apply them to whichever individual emails are relevant to that label, often with more than one label per email. The folder strategy recapitulates linnaean variation and the label strategy cartesian variation. I would love to have a system where labels are applied to emails but where labels are placed into a folder hierarchy. By never applying more than one label per email or never using more than one folder, either system can be recovered, but the mixed system broaches basically all my use cases.
6. See https://en.wikipedia.org/wiki/List_of_probability_distributions.

{kind=link}
{kind=link}