Recall that gravity is monovalently attractive. If you had two hydrogen atoms far apart in space, then the parameter space of the symposition of the two would have a dimension corresponding to the distance between them. The distance between them also has a corresponding gravitational potential energy associated with it. Farther distances correspond to more potential energy, and closer distances to less. Energy is conserved, however, so as the hydrogen atoms gravitate towards each other, the gravitational potential energy lost due to their getting closer is converted into kinetic energy, making them move with ever greater velocity as they approach each other. Just like a histogram or population density landscape can be constructed over a parameter space, a potential energy landscape can also be constructed over it as well. The parameter space of the symposition of the two hydrogen atoms has a potential landscape that reaches a minimum or valley when the two atoms are in the same place.
But that analysis is strictly gravitational. Atoms have primitives that also interact according to the other forces. The potential landscape from electromagnetism is more complicated, but suffice it say that it does not go to a minimum when the two hydrogen atoms are in the same place, but rather when they are about 7.4×10-11 meters apart. The overall potential landscape from the two forces is simply the sum of the two landscapes, at least until even smaller scales where the nuclear forces also become relevant. Since gravity in this context is overwhelmingly weaker than electromagnetism, the distance between the two atoms is almost completely dictated by electromagnetism.
In general, when primitives are attracted to each other by some force, the potential energy of their symposition is highest when they are separate, and vice-versa when they are repulsed, such as with a pair of electrons. Since the Dust was distributed almost homogeneously at the Big Bang, the Universe was born with an enormous reserve of potential energy in its gravitational form. We can repeat the story from Chapter 2 in terms of energy and potential landscapes. As primitives overcame the Jeans limit and collapsed together, the gravitational potential energy was converted into other forms of energy. First, it was converted into the kinetic energy of the primitives racing together. When they reached a sufficient density, the atoms began colliding violently with each other. The collisions often stripped the electrons from their nuclei, converting the kinetic energy of the atoms into the electromagnetic potential energy of the separation of electrons from their nuclei, along with kinetic energy for the dispersal of electrons and nuclei in their own directions.
With the nuclei stripped of their electrons, electron degeneracy pressure no longer walled the nuclei off from each other. The repulsion between nuclei continued, however, with the electromagnetic component of the potential landscape of two nuclei reaching a peak with the nuclei together and fused. The residual strong force component was the opposite, reaching a deep trough with the nuclei fused. The trough was much more narrow than the electromagnetic peak, however, because the residual strong force only operates at much closer distances. Thus the combined potential landscape from the electromagnetic and strong forces had two valleys, one with the nuclei far apart and one with the nuclei fused, separated by a high potential mountain. You can imagine trying to roll a bowling ball over a hill. With a fast enough roll, the ball would overcome the peak and roll into the valley on the other side; with a roll too slow, it would just go up and then come back down on the original side.1 Nuclei racing together with enough velocity and kinetic energy overcome the barrier of electromagnetic repulsion and enter the valley of residual strong attraction. For nuclei summing to the size of iron, the residual strong valley of fusion is deeper than the unfused valley. When these nuclei fuse, the drop in potential energy from the difference in depth of the valleys is converted to other forms, such as kinetic energy and electromagnetic radiation, or light, which eventually shines into space, illuminating planets like our own.
Ordinary nuclear fusion in stars does not produce elements substantially larger than iron because the depth of the residual strong valley of fusion is overcome by the height of the electromagnetic peak in these elements. The exceptional circumstances for the fusion of elements beyond iron occur during novae and supernovae, stellar explosions, processes which are too complicated to describe in detail here. When elements far beyond iron are created, they are quite often radioactive, with the peaks separating them from their radioactive products being relatively easy to overcome. When they fission or decay and drop back down to elements closer to iron, they release potential energy.
The release of energy from nuclear fission is the primary source of heat within Earth’s core. The gradual cooling of an object can be used to determine how old it is if one has a good estimate for its initial temperature. Lord Kelvin calculated the age of the Earth a century and a half ago using the correct assumption that it originated as molten, but he did not know about nuclear fission, so he underestimated Earth’s 4.5 billion years of age as being near 100 million years. Without radioactivity, Earth’s core would have cooled a long time ago. Once Earth’s core cools, there will no longer be dissipation of energy from it into space. Currently, that dissipation is the primary factor driving the motion of tectonic plates through the convective processes churning in Earth’s mantle. The motion of the plates powers enormous stresses in the solid materials of Earth’s crust. The stresses are carried by distortions in interatomic bonds, such that they are forced out of the comfort of the lowest points of their potential valleys and up the sides of potential mountains. With enough stress, the potential valleys are finally escaped, and the partonomic neighborhoods of the involved atoms can shift quickly in an earthquake. If the earthquake happens under the sea, it can displace massive amounts of water, throwing the sea out of its own potential valley resulting in a tsunami.
Let’s summarize the pathway of potential energy from Big Bang to tsunami. Primordial gravitational potential energy is used to overcome electromagnetic potential barriers to nuclear fusion. Particularly violent events like novae overshoot the lowest potential valley of iron nuclei, storing potential energy in larger radioactive nuclei. The stored nuclear potential energy is released in planet cores through radioactive decay, powering the convection of molten rock and the motion of tectonic plates. The energy from the motion of tectonic plates is stored in stressed interatomic bonds in rock. The electromagnetic potential energy in the stressed bonds is released in earthquakes, where it can differentially raise and lower sea level. The disrupted sea level packs the energy into gravitational potential energy, full circle from the Big Bang, where it dissipates in a series of waves that transfer the energy elsewhere. The overall story is rather simple: primitives want to flow energetically downhill in the landscapes over the parameter spaces of the sympositions they participate in, but they are blocked by many potential barriers. When they do succeed in flowing downhill, they release energy, which in turn interferes with other primitives flowing downhill.
The energy differential between the actual state of a system with its primitives stuck behind potential barriers and the state of the system where all of the primitives have tunneled through their barriers and into their lowest valleys is called exergy. About 5.9 million years ago, the Strait of Gibraltar closed, and the Mediterranean Sea dried up leaving a string of very salty lakes along its floor. This created a large differential in the sea levels of the terrestrial ocean and of the shriveled Mediterranean. You can imagine being an entrepreneur and building a mill on the closed strait, together with some canals to carry oceanic water over a mill-wheel that dumps into the Mediterranean basin. Unfortunately, after about 0.6 million years of hounding investors, your venture didn’t get funded because the strait reopened, triggering the Zanclean Deluge of the Mediterranean basin.2 Where there is a differential in the height of the neighboring bodies of water, a mill can be built to extract the exergy of the falling water. If there is no differential, a useful mill cannot be built. But even without the differential, there is still gravitational potential energy because the water on Earth hasn’t collapsed to a black hole.
It is interesting to ask how much of the energy right after the Big Bang was exergy. Apparently quite a bit of it was, and it would be fun if exactly all of it was, but this is an open question in physics. Regardless, we can look into the World and try to find the distribution of exergy. We have already discussed at length the exergy in simple gravitational, chemical, and nuclear systems. A system also has exergy whenever its partonomic neighborhood includes two or more sympositions at different temperatures; the hotter ones have exergy that can be extracted by letting the heat energy flow into the cooler ones. When they all reach the same temperature, no more exergy can be extracted. Aside from these examples, exergy resides in a complicated tangle of volume, pressure, temperature, and other factors, which are studied by the science of thermodynamics. We can see that the Sun harbors an enormous amount of exergy, as does Earth’s core. A simple way to find exergy is to find those sympositions that radiate heat; life forms do, as do electronic devices, automatic machines, and our homes in winter.
When exergy decreases, where does it go? Where did it go when the Atlantic refilled the Mediterranean? The event was probably very loud, so much of the exergy ended up as sound, which is just the coordinated oscillations of interatomic bond lengths of atoms and molecules of air as they are periodically displaced to and fro at the bottom of their potential valleys. These oscillations are also called “phonons.” Incidentally, heat is exactly as the same thing, except it includes all potential valleys, not just the ones of bond length, such as those from bond angles and rotations. Exergy is lost as it diffuses into the maze of partonomic neighborhoods in the Logos, where no symposition can coordinate a regathering of it all. On the surface of the Earth, the potential foothills that it gets lost among are almost always dependent upon electromagnetism, and the last destination for it is as electromagnetic radiation into space.
Finally, it’s worth addressing the relationship between symmetry and energy. Many of you may understand symmetry as being a rough measure of order. When energy is added to a system or partonomic neighborhood, its sympositions jostle about more, and thus one could expect its order to decrease with the addition of the energy. At a first pass, then, it seems that we could expect symmetry to decrease when energy increases. Enter barium titanate, BaTiO3. Barium titanate is a crystalline compound with interesting electromagnetic properties like photorefractivity and piezoelectricity that melts (or freezes) at 1625 ºC. If you freeze it through the melting point down to room temperature, it passes through a sequence of solid phases3 that have, in order, hexagonal, cubic, tetragonal, orthorhombic, and rhombohedral crystal structure, where each is a variant on the same unit cell symposition of barium, titanium, and oxygen ions. This sequence arranged by decreasing temperature in fact proceeds from more symmetry to less.
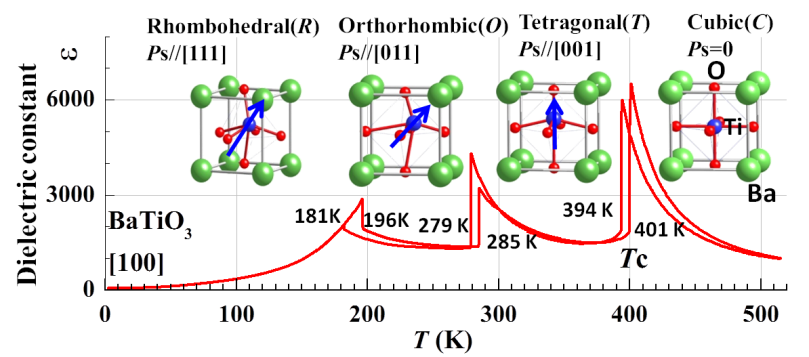 Figure 1. The unit cell of BaTiO3, at a variety of temperatures, with the dielectric constant plotted. Red spheres are oxygen ions, green barium ions, and blue titanium ions. http://www.intechopen.com/source/html/48777/media/image2.png
Figure 1. The unit cell of BaTiO3, at a variety of temperatures, with the dielectric constant plotted. Red spheres are oxygen ions, green barium ions, and blue titanium ions. http://www.intechopen.com/source/html/48777/media/image2.png
A parameter space for the unit cell sympositions for each phase can be constructed whose dimensions measure bond lengths and bond angles between adjacent ions. A small chunk of barium titanate has far more than trillions of ions, so the histogram over the parameter space has similarly many datapoints. Each phase has a different histogram. The hottest phase has the broadest modes, since the individuals are jostling about so much and can’t decide quite where to be, and conversely the coolest phase has the narrowest modes. As the small chunk is cooled, a given mode gets narrower and narrower until a thermodynamic breaking point where it fractures into several pieces. At a high temperature, the titanium ion bounces all around the center of the unit cell, but on average, it is exactly in the middle; at low temperature, the titanium ion picks a direction and shifts off-center, breaking the symmetry with the other ions in the unit cell. Thus the symmetry is broken at the level of interatomic poses, but it is also broken on a higher level: the off-center shift propagates from one unit cell to the next, until it reaches another wave of propagation that decided to shift in another one of the possible directions. If we assume that the small chunk started out at the higher temperature as monocrystalline, that is as a single perfect repeating lattice all throughout, then it can easily end up partitioned into multiple crystal grains, probably separated by twin boundaries.4 This partitioning entails the insertion of a level into the partonomy.
We can see that the association between energy and symmetry is the opposite from what one might expect: partonomic neighborhoods with more energy have more symmetry, not less. At the Big Bang, all partonomic neighborhoods were in enormously high energy states, and these correspond to the known homogeneity of the quark-gluon plasma. What happened before the quark-gluon plasma kindles current research into theories of supersymmetry. As the Universe has embarked on lower energy states after the Big Bang, a cascade of broken symmetries in many partonomic neighborhoods has resulted in a fracturing of populations leading directly to the infilling of partonomic gaps with more levels and the growth of the Logos upon the Dust.
Footnotes
1. A more realistic illustration accounts for the fact that it’s more like two balls participating together in the construction of a hill to divide them.
2. Dramatized by xkcd: http://xkcd.com/1190/
3. In general, a solid of a given compound can have many phases at different temperatures (and pressures), but the compound will have only one liquid phase and only one gaseous phase.
4. http://www.tandfonline.com/doi/abs/10.1080/14786444908561371


{kind=link}
{kind=link}
{kind=link}